Prezado leitor,
Se você trabalha com dados geoespaciais, principalmente rasters, provavelmente já esbarrou em problemas como:
- Dificuldade de organizar grandes volumes de dados
- Falta de padronização na publicação
- APIs pouco eficientes para busca espacial/temporal
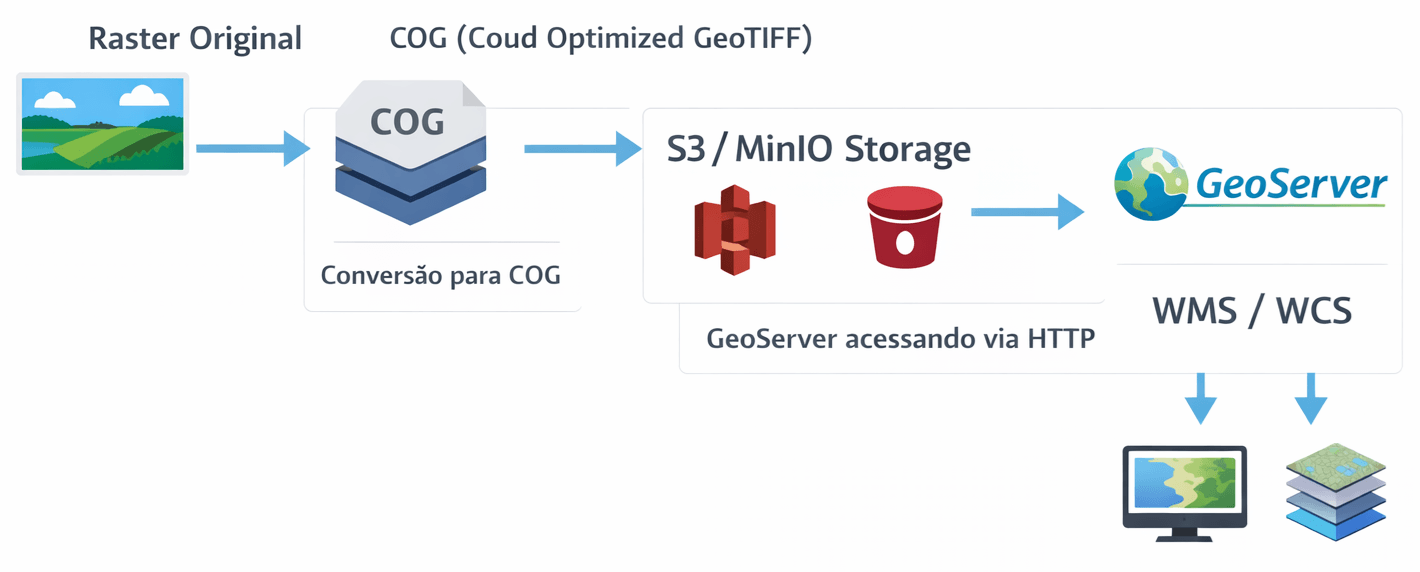
É exatamente aqui que entra o STAC (SpatioTemporal Asset Catalog). Mais do que um formato, o STAC é um padrão moderno para organizar, catalogar e acessar dados geoespaciais, permitindo buscas rápidas e interoperáveis.
Neste guia, você vai aprender a montar um ambiente completo para:
- Organizar seus dados no padrão STAC
- Publicar via API moderna
- Integrar com o GeoServer
- Servir dados raster (COG) de forma eficiente
Este post apresenta, passo a passo, como montar um ambiente completo para criação e publicação de um catálogo STAC (SpatioTemporal Asset Catalog), utilizando Docker, PostGIS, GeoServer e uma API intermediária (adapter). O objetivo é permitir que você organize, publique e consuma dados geoespaciais modernos de forma eficiente.
Antes de começar, é importante entender o papel de cada componente:
- PostGIS → Armazena os metadados espaciais
- pgSTAC → Implementa o padrão STAC dentro do PostgreSQL
- STAC FastAPI → Expõe os dados via API REST
- GeoServer → Publica e renderiza os dados
- Adapter (FastAPI) → Traduz STAC para o formato esperado pelo GeoServer
Um ponto importante: o GeoServer ainda não consome STAC “puro” de forma completa, por isso o uso do adapter é essencial.
1. Atualização do sistema
Antes de instalar qualquer ferramenta, é importante garantir que o sistema esteja atualizado. Isso evita problemas de dependência e incompatibilidade.
> sudo apt update
> sudo apt upgrade -y
2. Instalação do Docker
O Docker será usado para isolar cada componente da arquitetura, garantindo reprodutibilidade. Isso evita conflitos de versão e facilita deploy em outros ambientes.
2.1 Adicionar chave GPG:
> curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
> sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
2.2 Adicionar repositório:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
2.3 Instalar Docker + Compose:
> sudo apt update
> sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
Com isso, você terá um ambiente isolado para rodar toda a stack sem conflitos de versão.
3. Estrutura do projeto
Agora vamos organizar os diretórios do projeto:
> sudo mkdir -p /docker/geoserver/plugins
> cd /docker/geoserver/plugins
4. Download dos plugins do GeoServer
O plugins que iremos realizar o download adicionam suporte a:
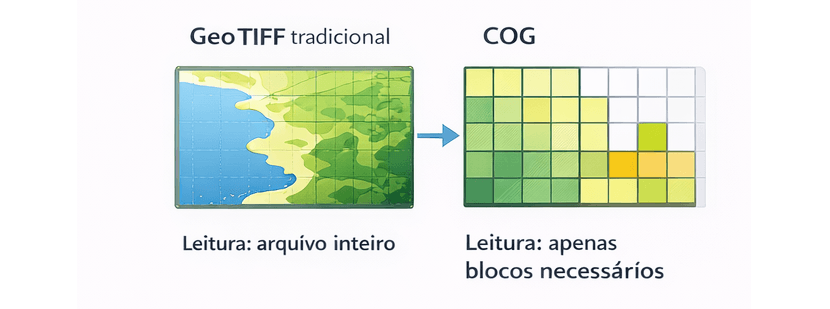
- COG (Cloud Optimized GeoTIFF) via HTTP/S3
- Integração com STAC
Sem esses plugins, o GeoServer não consegue trabalhar corretamente com dados cloud-native.
> wget https://build.geoserver.org/geoserver/2.27.x/community-latest/geoserver-2.27-SNAPSHOT-cog-http-plugin.zip
> wget https://build.geoserver.org/geoserver/2.27.x/community-latest/geoserver-2.27-SNAPSHOT-cog-s3-plugin.zip
> wget https://build.geoserver.org/geoserver/2.27.x/community-latest/geoserver-2.27-SNAPSHOT-stac-datastore-plugin.zip
5. Dockerfile do GeoServer
Criamos um Dockerfile para incluir os plugins:
cd /docker/geoserver
nano Dockerfile
O conteúdo do arquivo:
FROM docker.osgeo.org/geoserver:2.27.2
COPY plugins/*.jar /usr/local/tomcat/webapps/geoserver/WEB-INF/lib/
Aqui estamos estendendo a imagem padrão do GeoServer para suportar STAC e COG.
6. Arquivo Docker Compose
Agora definimos toda a infraestrutura: Banco de dados (PostGIS), API STAC e GeoServer. Vamos então criar o arquivo docker-compose.yaml:
cd /docker
nano docker-compose.yaml
Esse arquivo é o coração da infraestrutura, ele define como os serviços se comunicam e persistem dados. O conteúdo do arquivo:
volumes:
postgis-data:
geoserver-data:
networks:
internal:
external:
services:
db:
container_name: postgis
image: postgis/postgis:16-3.4
volumes:
- postgis-data:/var/lib/postgresql/data
environment:
- POSTGRES_DB=postgis
- POSTGRES_USER=postgis
- POSTGRES_PASSWORD=senha_postgis
- IP_LIST=*
- ALLOW_IP_RANGE=0.0.0.0/0
- POSTGRES_MULTIPLE_EXTENSIONS=postgis,hstore,postgis_topology,postgis_raster,pgrouting,btree_gist
- FORCE_SSL=false
ports:
- "5432:5432"
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgis-d postgis"]
interval: 5s
timeout: 5s
retries: 10
networks:
- internal
geoserver:
container_name: geoserver
build: ./geoserver
volumes:
- geoserver-data:/opt/geoserver/data_dir
- /docker/geoserver/imagem_raster:/opt/geoserver/data_dir/coverages
environment:
- TZ=America/Sao_Paulo
- GEOSERVER_ADMIN_USER=admin
- GEOSERVER_ADMIN_PASSWORD=geoserver
- INSTALL_EXTENSIONS=true
- EXTRA_JAVA_OPTS=-Xms4G -Xmx6G
- STABLE_EXTENSIONS=importer,wps,pyramid
- PROXY_BASE_URL=http://192.168.186.140:8083/geoserver
- GEOSERVER_CSRF_WHITELIST=192.168.186.140
- HTTP_SCHEME=http
- CORS_ENABLED=false
ports:
- "8083:8080"
restart: unless-stopped
healthcheck:
test: curl --fail "http://localhost:8080/geoserver/web/wicket/resource/org.geoserver.web.GeoServerBasePage/img/logo.png" || exit 1
interval: 1m30s
timeout: 10s
retries: 3
networks:
- internal
- external
stac:
container_name: stac-api
image: ghcr.io/stac-utils/stac-fastapi-pgstac:latest
environment:
- PGHOST=db
- PGPORT=5432
- PGDATABASE=postgis
- PGUSER=postgis
- PGPASSWORD=senha_postgis
ports:
- "8085:8080"
depends_on:
db:
condition: service_healthy
networks:
- internal
Agora é subir o ambiente:
> docker compose build
> docker compose up -d
7. Criar banco STAC (pgstac)
Instalar a ferramenta:
sudo apt install -y pipx
pipx ensurepath
source ~/.bashrc
pipx install "pypgstac[psycopg]"
Configurar conexão:
export PGHOST=127.0.0.1
export PGPORT=5432
export PGDATABASE=postgis
export PGUSER=postgis
export PGPASSWORD=senha_postgis
Rodar migração:
> pypgstac migrate
Esse comando cria toda a estrutura STAC dentro do banco:
- Tabelas de collections
- Tabelas de items
- Índices espaciais e temporais
Sem isso, a API STAC não consegue funcionar.
8. Criar Collection
Collections funcionam como agrupadores lógicos de dados. Exemplos: Sentinel-2, Ortofotos, Modelos de elevação.
Crie o arquivo:
nano collection.json
Conteúdo do arquivo:
{
"id": "raster-test",
"type": "Collection",
"description": "Teste de raster",
"license": "proprietary",
"extent": {
"spatial": { "bbox": [[-180, -90, 180, 90]] },
"temporal": { "interval": [["2024-01-01T00:00:00Z", null]] }
}
}
Para inserir no banco, execute o comando abaixo:
pypgstac load collections collection.json
9. Criar itens
Os Items representam os dados reais. Exemplo: Um raster específico, um ortomosaico, uma cena de satélite.
Crie o arquivo:
nano item.json
Conteúdo do arquivo:
{
"type": "Feature",
"stac_version": "1.0.0",
"id": "paraiso-ortomosaico",
"collection": "raster-test",
"geometry": {
"type": "Polygon",
"coordinates": [[
[-48.8961561, -25.0593974],
[-48.8764276, -25.0593974],
[-48.8764276, -25.0730781],
[-48.8961561, -25.0730781],
[-48.8961561, -25.0593974]
]]
},
"bbox": [-48.8961561,-25.0730781,-48.8764276,-25.0593974],
"properties": {
"datetime": "2024-01-01T00:00:00Z",
"proj:epsg": 4326
},
"assets": {
"data": {
"href": "http://SEU_IP:9000/rasters/seu_arquivo.tif",
"type": "image/tiff",
"roles": ["data"]
}
}
}
Inserir item no banco:
pypgstac load items item.json
Se você precisar editar o conteúdo do json e realizar um update no banco, use o seguinte comando:
pypgstac load items item.json --method upsert
Você ainda tem uma outra opção que é a criação automático do arquivo json através do rio-stac, para isso você precisa:
pipx install rio-stac --include-deps
rio stac orotomosaico_cog.tif > item.json
Dica importante:
O campo “href”: “http://SEU_IP:9000/rasters/seu_arquivo.tif” do JSON, é o link para o dado real (idealmente um COG acessível via HTTP ou S3).
10. Adapter STAC (compatibilidade com GeoServer)
Essa é uma das partes mais importantes da arquitetura, pois o GeoServer não consume STAC de forma totalmente nativa. Então esse adapter vai resolver as incompatibilidades do GeoServer com STAC, ajustando links e headers.
Para o STAC funcionar perfeitamente no GeoServer, é necessário realizar alguns ajustes de:
- Content-Type
- Href
- Navegação interna
Devido a esse problema, foi desenvolvido um adapter em FastAPI que: intercepta requisições, ajusta os links (href), corrige headers e diferencia chamadas internas e externas.
Criar API:
mkdir /docker/api
cd /docker/api
nano adapter.py
Conteúdo do arquivo adapter.py
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
import requests
import os
app = FastAPI()
STAC_URL = "http://stac-api:8080"
# URLs
PUBLIC_URL = os.getenv("PUBLIC_URL", "http://192.168.186.140:8087")
INTERNAL_URL = "http://stac-adapter:8081"
# -------------------------
# Helper para requisições
# -------------------------
def fetch(url, method="GET", json=None):
if method == "POST":
r = requests.post(url, json=json)
else:
r = requests.get(url)
r.raise_for_status()
return r.json()
# -------------------------
# Detecta se é chamada interna (GeoServer)
# -------------------------
def is_internal(request: Request):
host = request.headers.get("host", "")
return "stac-adapter" in host or "geoserver" in host
# -------------------------
# Fix links (inteligente)
# -------------------------
def fix_links(data, internal=False):
base = INTERNAL_URL if internal else PUBLIC_URL
def fix(obj):
if isinstance(obj, dict):
for k, v in obj.items():
if k == "href" and isinstance(v, str):
obj[k] = v.replace("http://stac-api:8080", base)
else:
fix(v)
elif isinstance(obj, list):
for item in obj:
fix(item)
fix(data)
return data
# -------------------------
# ROOT
# -------------------------
@app.api_route("/", methods=["GET", "HEAD"])
async def root(request: Request):
data = fetch(f"{STAC_URL}/")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/json"
)
# -------------------------
# COLLECTIONS
# -------------------------
@app.api_route("/collections", methods=["GET", "HEAD"])
async def collections(request: Request):
data = fetch(f"{STAC_URL}/collections")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/json"
)
# -------------------------
# COLLECTION
# -------------------------
@app.api_route("/collections/{collection_id}", methods=["GET", "HEAD"])
async def collection(collection_id: str, request: Request):
data = fetch(f"{STAC_URL}/collections/{collection_id}")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/geo+json"
)
# -------------------------
# ITEMS
# -------------------------
@app.api_route("/collections/{collection_id}/items", methods=["GET", "HEAD"])
async def items(collection_id: str, request: Request):
data = fetch(f"{STAC_URL}/collections/{collection_id}/items")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/geo+json"
)
# -------------------------
# ITEM ESPECÍFICO
# -------------------------
@app.api_route("/collections/{collection_id}/items/{item_id}", methods=["GET", "HEAD"])
async def item(collection_id: str, item_id: str, request: Request):
data = fetch(f"{STAC_URL}/collections/{collection_id}/items/{item_id}")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/geo+json"
)
# -------------------------
# SEARCH
# -------------------------
@app.api_route("/search", methods=["GET", "POST", "HEAD"])
async def search(request: Request):
if request.method == "POST":
body = await request.json()
data = fetch(f"{STAC_URL}/search", method="POST", json=body)
else:
data = fetch(f"{STAC_URL}/search")
return JSONResponse(
content=fix_links(data, internal=is_internal(request)),
media_type="application/geo+json"
)
Agora vamos ao conteúdo do arquivo Dockerfile:
FROM python:3.11-slim
WORKDIR /app
RUN pip install fastapi uvicorn requests
COPY adapter.py .
CMD ["uvicorn", "adapter:app", "--host", "0.0.0.0", "--port", "8081"]
E pra finalizar, você deve adicionar ao seu docker-compose:
adapter:
container_name: stac-adapter
build: ./api
ports:
- "8087:8081"
depends_on:
- stac
networks:
- internal
- external
Agora é só subir o adapter:
docker compose up -d --build
11. Nginx
Agora, para finalizar, vamos instalar o nginx e deixar tudo rodando externamente na porta 80. O Nginx atua como proxy reverso, centralizando o acesso:
- /geoserver → GeoServer
- /stac → Adapter
- /stac-api → API direta
E ainda ajuda na organização das rotas, facilidade de exposição externa e melhor controle de segurança.
Vamos criar o arquivo nginx-stac.conf:
cd /docker/
nano nginx-stac.conf
Esse arquivo deve conter o seguinte conteúdo:
server {
listen 80;
# -------------------------
# GEOSERVER
# -------------------------
location /geoserver/ {
proxy_pass http://geoserver:8080/geoserver/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
# -------------------------
# STAC (via adapter)
# -------------------------
location /stac/ {
proxy_pass http://adapter:8081/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
# -------------------------
# STAC DIRETO (opcional)
# -------------------------
location /stac-api/ {
proxy_pass http://stac-api:8080/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
Você precisar alterar a seguinte linha do arquivo adapter.py:
PUBLIC_URL = os.getenv("PUBLIC_URL", "http://192.168.186.140:8087")
Para:
PUBLIC_URL = os.getenv("PUBLIC_URL", "http://192.168.186.140/stac")
Agora é só subir o seu container, e pronto:
docker compose up -d --build
Se tudo estiver correto, você verá sua collection retornada via API.
12. Conclusão
Com essa arquitetura, você passa a ter:
- Um catálogo STAC estruturado e escalável
- Uma API moderna para consulta espacial e temporal
- Integração com GeoServer
- Suporte a dados cloud-native (COG)
Mais do que isso, você construiu uma base sólida para aplicações geoespaciais modernas, preparada para lidar com grandes volumes de dados de forma eficiente.




 </figure>
</figure>
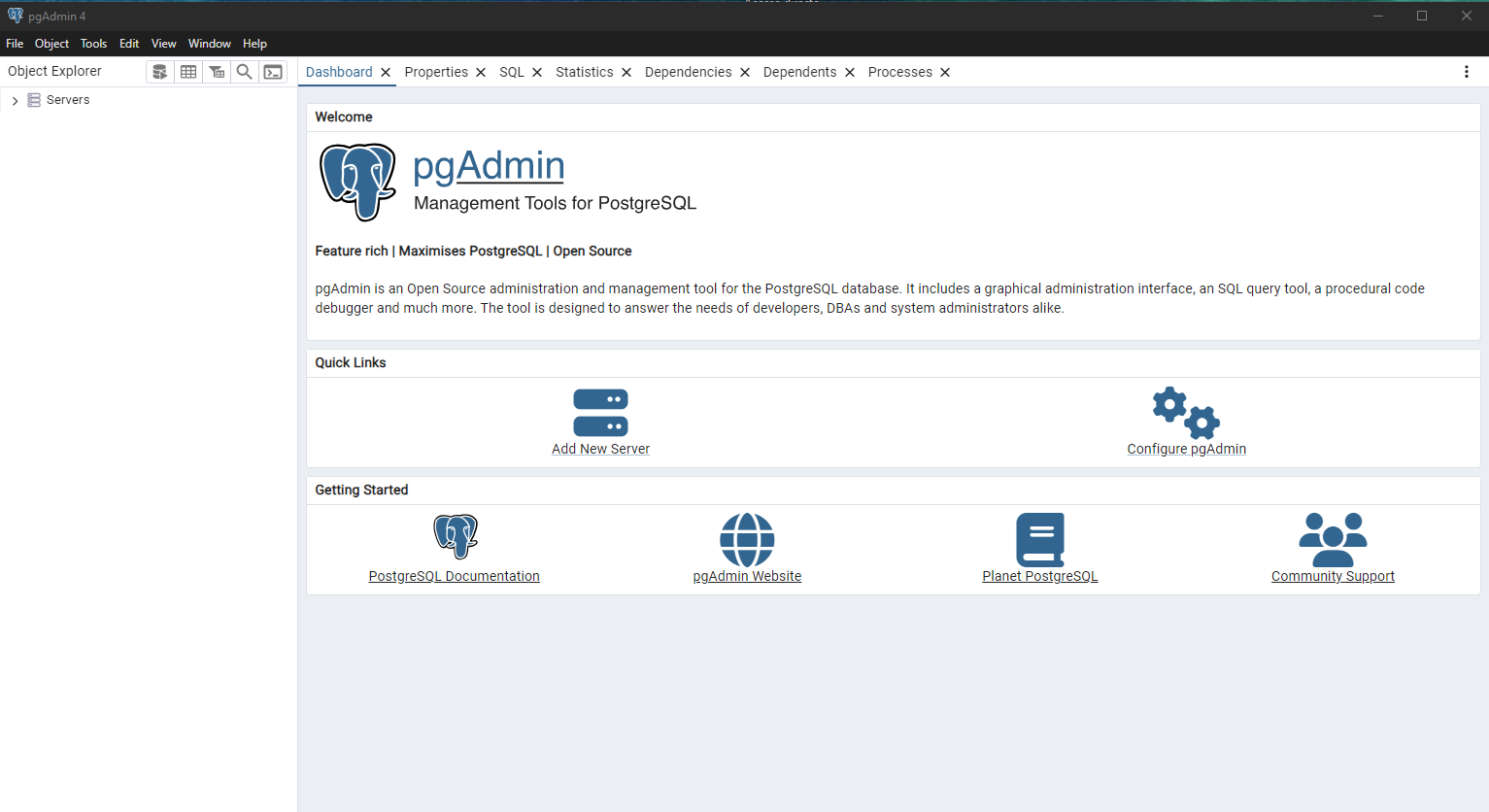
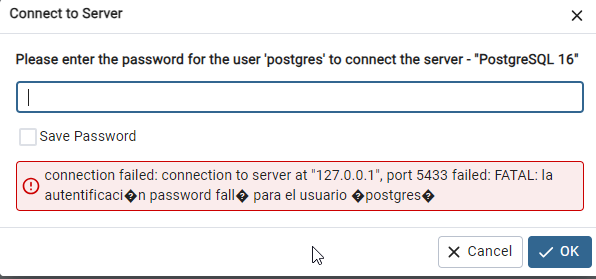
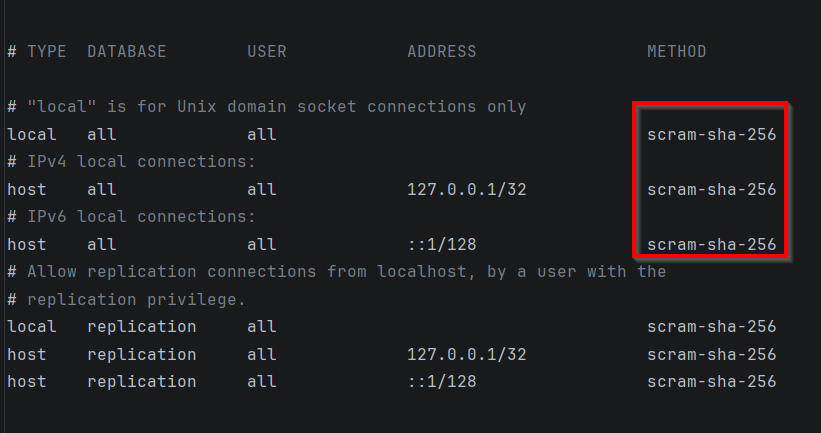


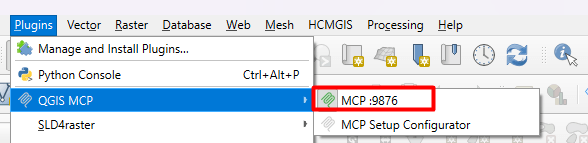
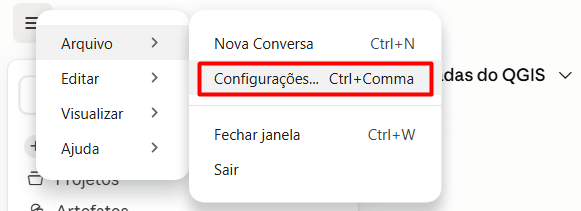
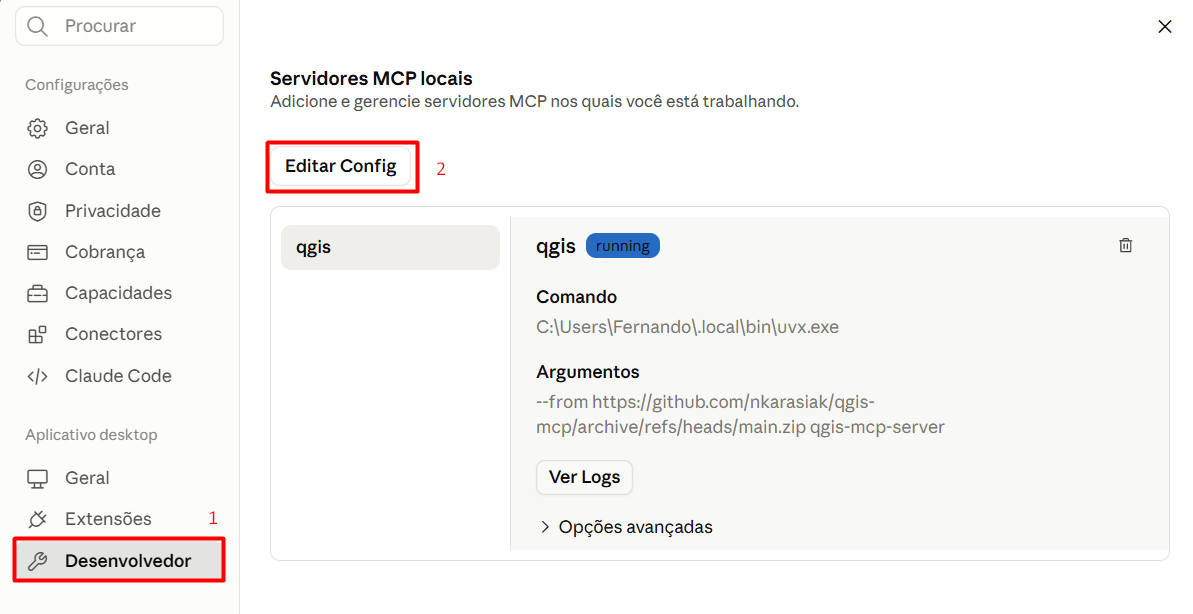
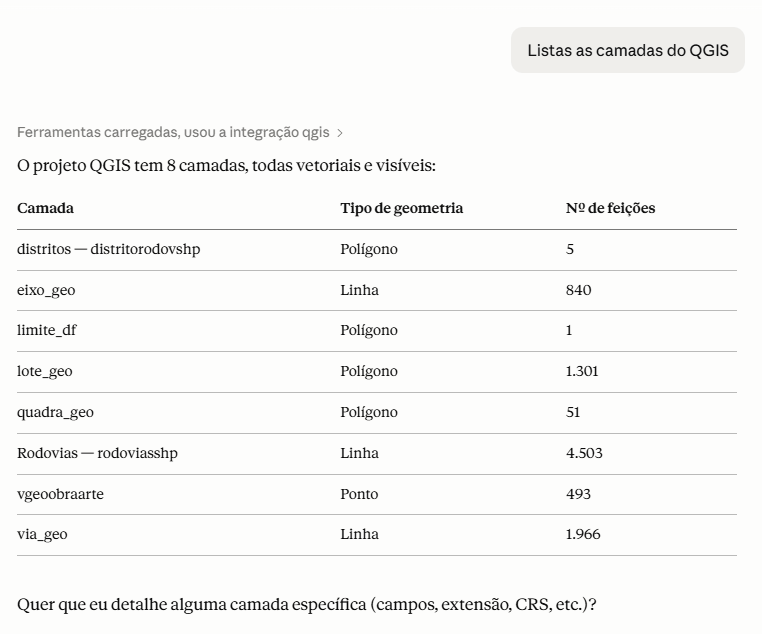

















 Você sabe transformar isso em uma solução acessível na web?
Você sabe transformar isso em uma solução acessível na web? Gerar mapas
Gerar mapas Não.
Não. PostgreSQL + PostGIS
PostgreSQL + PostGIS GeoServer
GeoServer GeoNode
GeoNode Na prática, isso significa que você será capaz de:
Na prática, isso significa que você será capaz de:


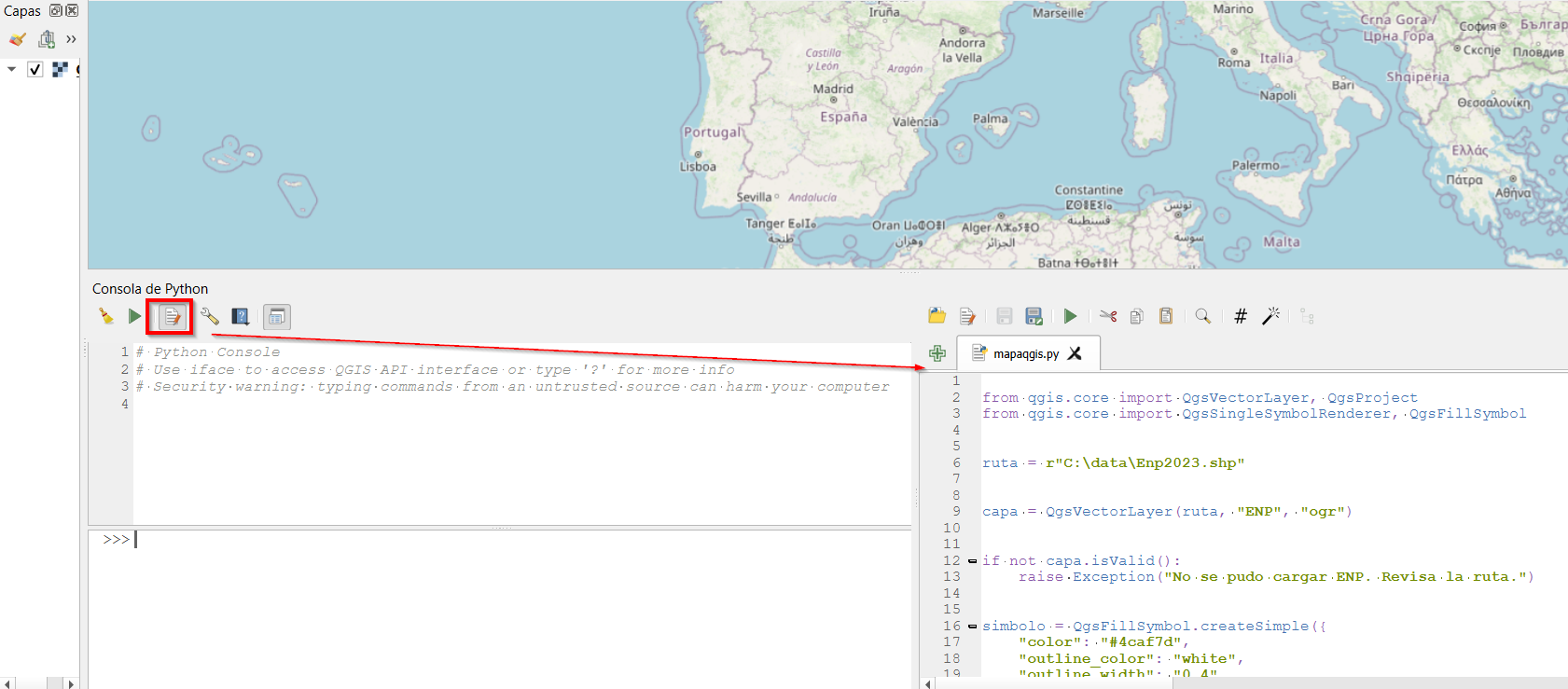


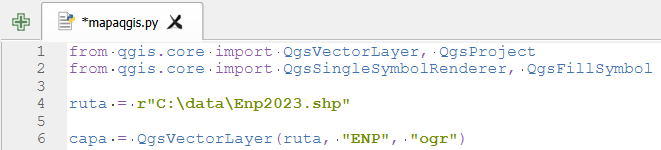
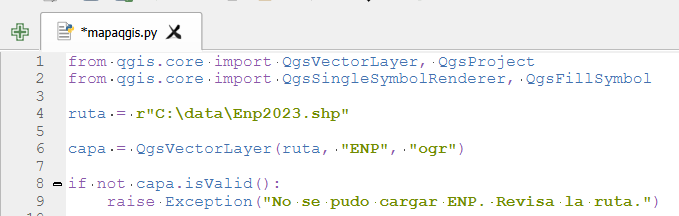
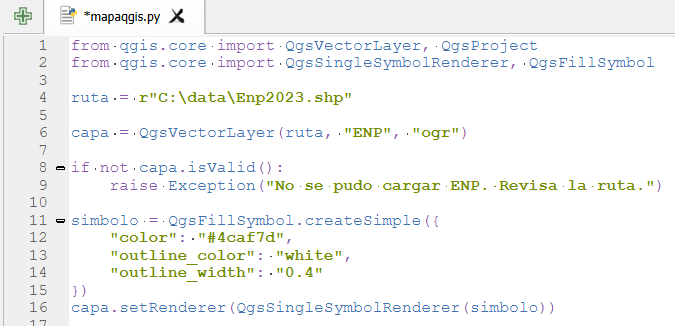
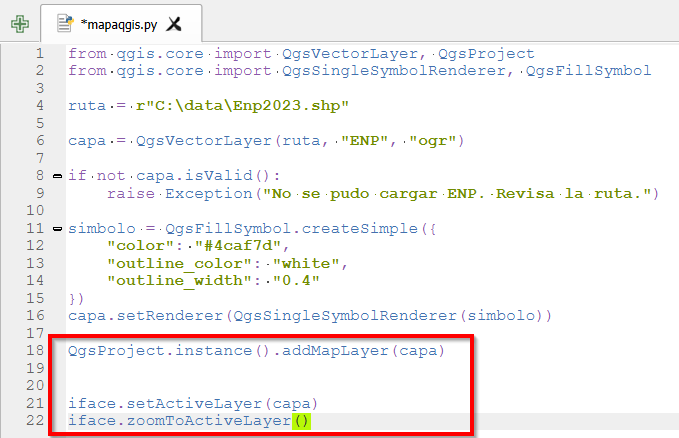
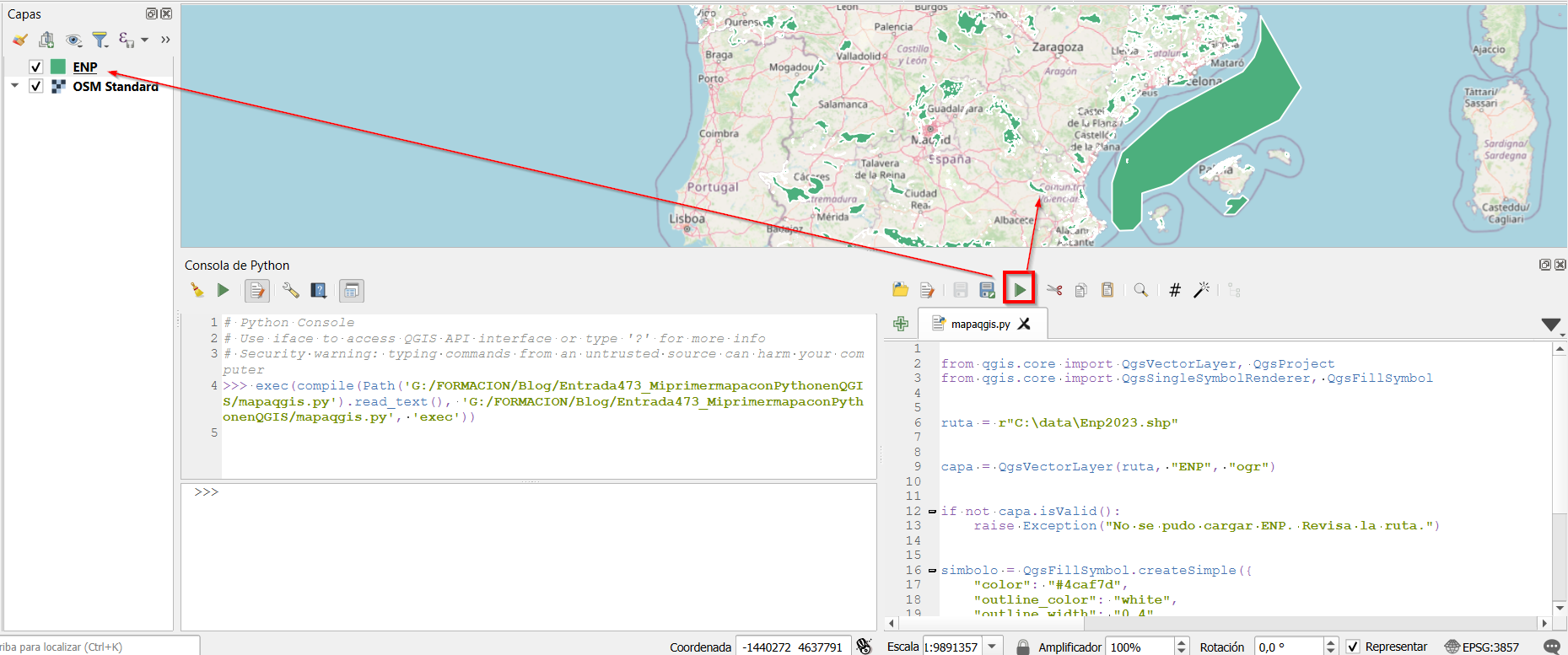
























 El contexto: hoja de ruta de QGIS 4.x y Qt6
El contexto: hoja de ruta de QGIS 4.x y Qt6
 Qué implica realmente el salto a QGIS 4.0
Qué implica realmente el salto a QGIS 4.0 Adaptación del ecosistema y validación técnica
Adaptación del ecosistema y validación técnica
 Estándares e interoperabilidad como elemento estabilizador
Estándares e interoperabilidad como elemento estabilizador Caso práctico: validar el entorno tras la migración
Caso práctico: validar el entorno tras la migración
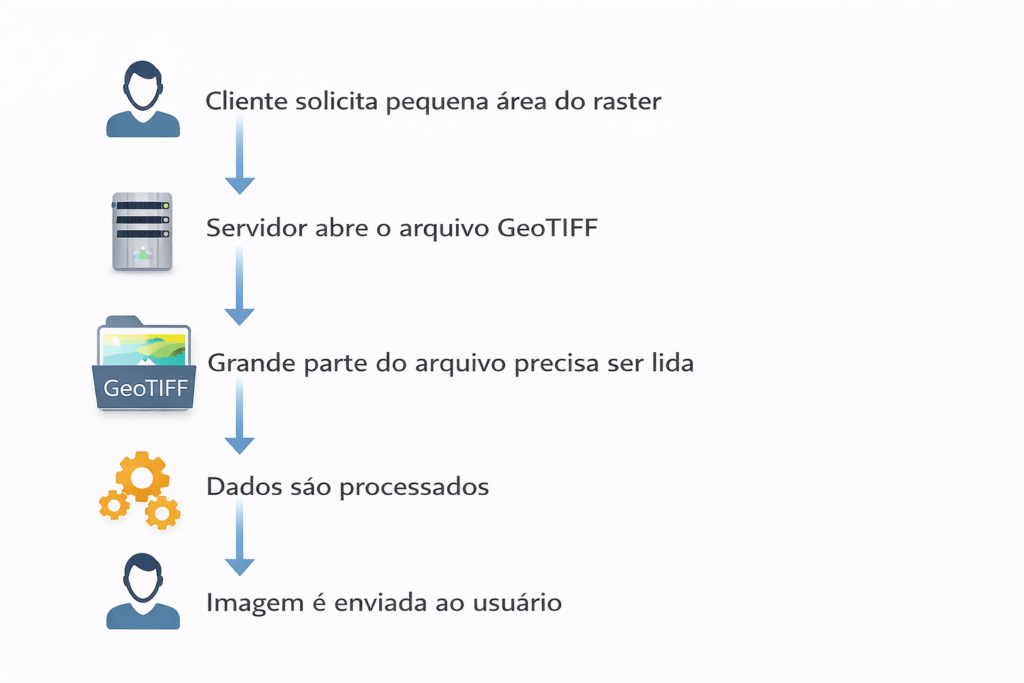

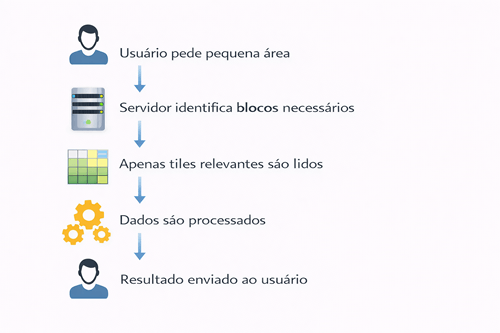

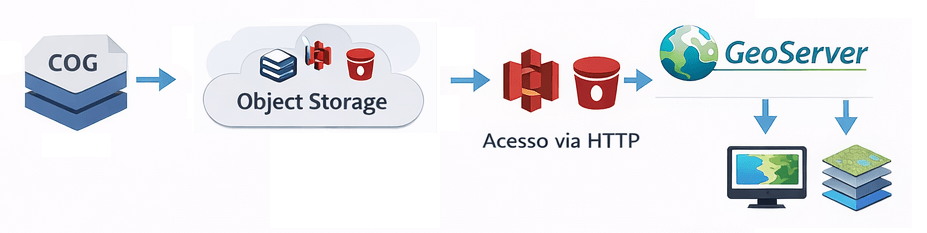
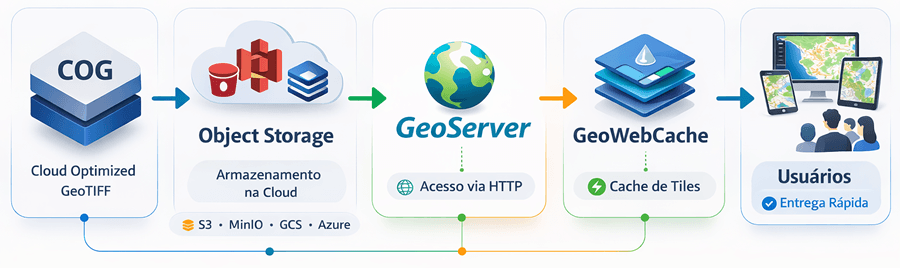


















 O que você vai dominar:
O que você vai dominar: Python do zero com foco técnico
Python do zero com foco técnico Para quem é este curso?
Para quem é este curso? Profissionais de GIS e Geoprocessamento
Profissionais de GIS e Geoprocessamento Vagas limitadas
Vagas limitadas





 Se você não pôde participar presencialmente ou deseja rever os conteúdos apresentados, todos os vídeos das palestras estão disponíveis gratuitamente no nosso canal do YouTube!
Se você não pôde participar presencialmente ou deseja rever os conteúdos apresentados, todos os vídeos das palestras estão disponíveis gratuitamente no nosso canal do YouTube! Continue acompanhando nossas redes sociais e site para ficar por dentro dos próximos encontros, oficinas e oportunidades de capacitação!
Continue acompanhando nossas redes sociais e site para ficar por dentro dos próximos encontros, oficinas e oportunidades de capacitação!
